Generative Adversarial Networks

The final project for my Deep Learning course completed in collaboration with Ben Fisk.
This project revolved around implementing Generative Adversarial Networks (GANs) to produce synthetic images which look visually similar to the training data. GANs are a type of generative deep model which aim to replicate training data by simultaneously training a generator and a discriminator. The two components of the GAN play a two-player mini-max game where the generator aims to trick the discriminator into believing its generated examples are part of the real dataset while the discriminator is trying to maximize its ability to correctly distinguish between real and fake data. For more information on how GANs work, I recommend reading the original paper by Goodfellow et. al. (2014).
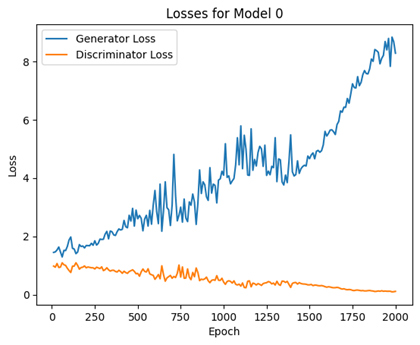
We began this project by implementing a simple multi-layer perceptron GAN (MLP-GAN) on the CIFAR-10 dataset. We were able to get some decent results from this model – the produced images showed a good amount of structure. However, the results were blurry at best and we were unable to produce any clearly distinguishable images that looked like the object classes in the training data (figure 1). We also came across some of the disadvantages of using GANs, namely mode collapse and inbalanced generators and discriminators (figure 2). When training our MLP-GAN, we noticed that we would reach peak fidelity after several hundred epochs and subsequent training would exacerbate noise and mode collapse as the generator loss increased (figure 3).


After training our MLP-GAN, we recieved some feedback stating that we could test our model architecture by training it on a single example and seeing if our generator could reproduce it. So, we tested it with our MLP-GAN and we saw that it was able to reproduce a single training example. However, we also noticed some interesting behaviour where it seemed at some point, the training seemed to collapse. The model would reach a point where it seemed to perfectly reproduce the target example but then would get increasingly noisy afterwards (figure 4).

Our next goal was to implement a Convolutional GAN for various datasets including MNIST, CIFAR-10, and ImageNet. We had to develop different model architectures for each dataset due to each having different data representations (i.e., mnist is black and white with 28x28 pixel size, CIFAR-10 is RGB with 32x32 pixel size, and ImageNet is RGB with a cropped down 64x64 pixel size). We tested the model architectures by training each on a single example (see figures 5-7).



Once we had confirmed our model architectures were able to produce images, we trained each model on several thousand examples of the training data. Below are the training progression for each of our models followed by a larger sample of images produces by the best checkpoints of our models.






None of the models we trained were able to produce examples that were indistinguishable from real examples based on our comparison, nor were they able to achieve good FID scores. Our best Convolutional GAN models got a score of 21.29 on MNIST, 24.69 on CIFAR-10, and 41.49 on ImageNet. However, among the hundreds of examples we produced, we were able to pick out a few interesting examples which seemed to resemble actual classes in our training data:



Other produced examples were not necessarily distinguishable by a particular class but had interesting aesthetic qualities:
